
在大数据分布式计算框架中,Shuffle是影响计算性能的很重要的一环。无论是MapReduce框架还是Spark计算框架,都有Shuffle的概念。本文总结分析Spark Shuffle的设计和实现。
[toc]
1、 理解MR框架中的Map和Reduce
在MapReduce框架中,Shuffle是介于Map和Reduce两个阶段之间,也称作Map和Reduce的连接桥梁。
Map阶段实现Sheffle阶段的数据写入(或称作数据持久化),对应Shuffle Write。
Reduce阶段实现Shuffle阶段的数据读取。对应Shuffle Read。
2、Spark Shuffle 的框架
由于Shuffle的设计与实现决定着计算性能的优劣,所以Spark在设计之初,就对外提供了统一的接口 ShuffleManager,方便后续的扩展,用户可以自定义实现,实现可插拔性。下图是Spark3.1的接口:
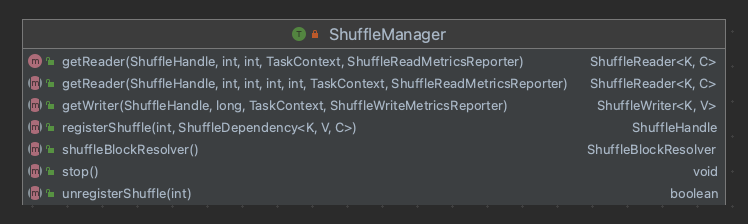
- getReader:Reduce通过ShuffleHandle获取ShuffleReader。
- getWriter:Map通过ShuffleHandle获取ShuffleWriter。
- registerShuffle:RDD通过依赖关系注册shuffle,获取ShuffleHandle,最终是通过ShuffleHandle来获取读和写。
- shuffleBlockResolver:shuffle的块解析器,和数据块之间构建关联关系。
其余方法顾名思义。
3、Spark Shuffle框架的演进图
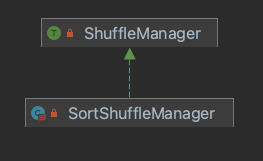
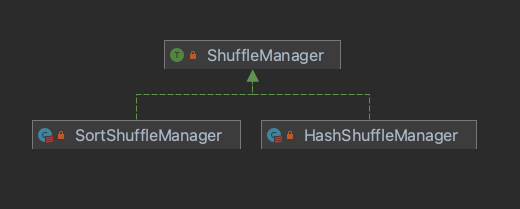
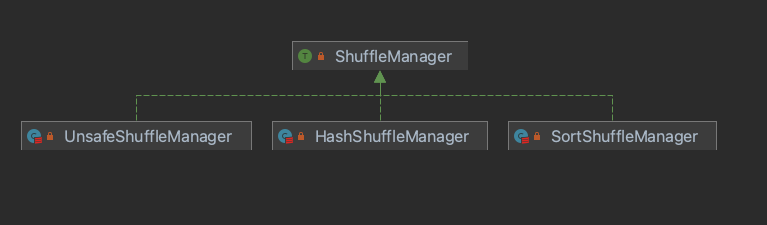
随着Spark版本的迭代,整体Shuffle的演进也是变化蛮大的。从Spark1.1分支开始,引入ShuffleManager接口,统一封装了SparkShuffle的框架。演进图如下:
1.1版本:
1.4版本
1.6版本
2.4+版本
从Shuffle架构设计之初,Spark Shuffle设计者提供了两种方案:hash和sort,而默认推荐使用hash(当时应该sort还不是很完善)。1.1版本中:
1 | // Let the user specify short names for shuffle managers |
1.2版本便开始默认使用sort,官方开始推荐使用SortShuffle。
钨丝计划中引入了一种新的优化方案:UnsafeShuffleManager。在1.4+版本中,用户可以通过指定spark.shuffle.manager=tungsten-sort来使用unsafe方案:
1 | // Let the user specify short names for shuffle managers |
然而unsafe顾名思义存在使用风险,这种完全将风险评估交给使用方的体验十分不友好。
我们可以看到,自1.6版本后,不再对外提供钨丝计划中的unsafe方案。unsafe开始作为sort方案的一种策略,是否启用由Spark来进行分析,这个动作是交给ShuffleHandler来完成的。
1 | // Let the user specify short names for shuffle managers |
自2.0版本开始,我们看到hash方案官方已经移除了。[SPARK-14667] Remove HashShuffleManager
1 | // Let the user specify short names for shuffle managers |
4、不同ShuffleManager的实现
4.1、HashShuffleManager
4.1.1、最初版的HashShuffle实现
在最初的版本中,Spark采用的是HashShuffle机制。
下图是Spark0.5版本中的HashShuffle原理:
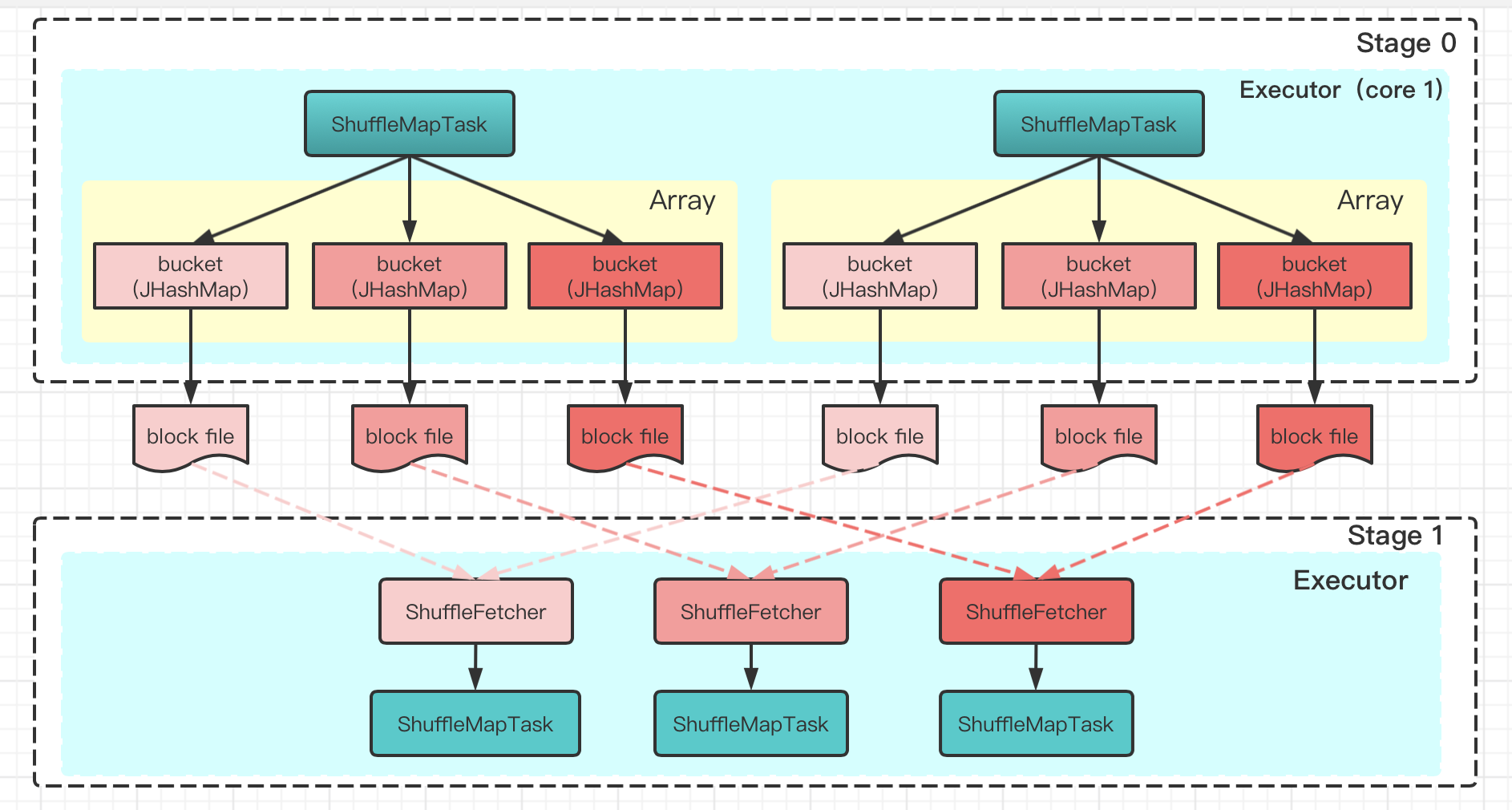
HashShuffle的特点:
- 每个map task会为每一个reduce task创建一个bucket缓存,每个bucket缓存最终会落盘一个文件
- bucket缓存底层是一个JHashMap,数据会根据key的hash值最终写到对应的bucket中去
这种实现存在的问题:
- shuffle文件数较大。M个map,R个reduce时,会落盘M*R个文件(更多的是小文件)。网络带宽等会成为瓶颈。
- bucket是将数据存储在HashMap结构的内存中,当数据量较大时,容易导致内存溢出。
在Spark0.6版本中,主要有两个变化:
- 1)增加了是否在Map侧进行数据预聚合的逻辑
- 2)写文件落盘通过BlockManager来进行管理
4.1.2、改进版的HashShuffle实现
为解决M*R个文件数问题,在Spark0.8版本代码中,引入了一个开关spark.shuffle.consolidateFiles,并通过BlockManager控制多个task写同一个bucket文件,跳过了之前的bucket HashMap结构,直接写文件。架构如下:
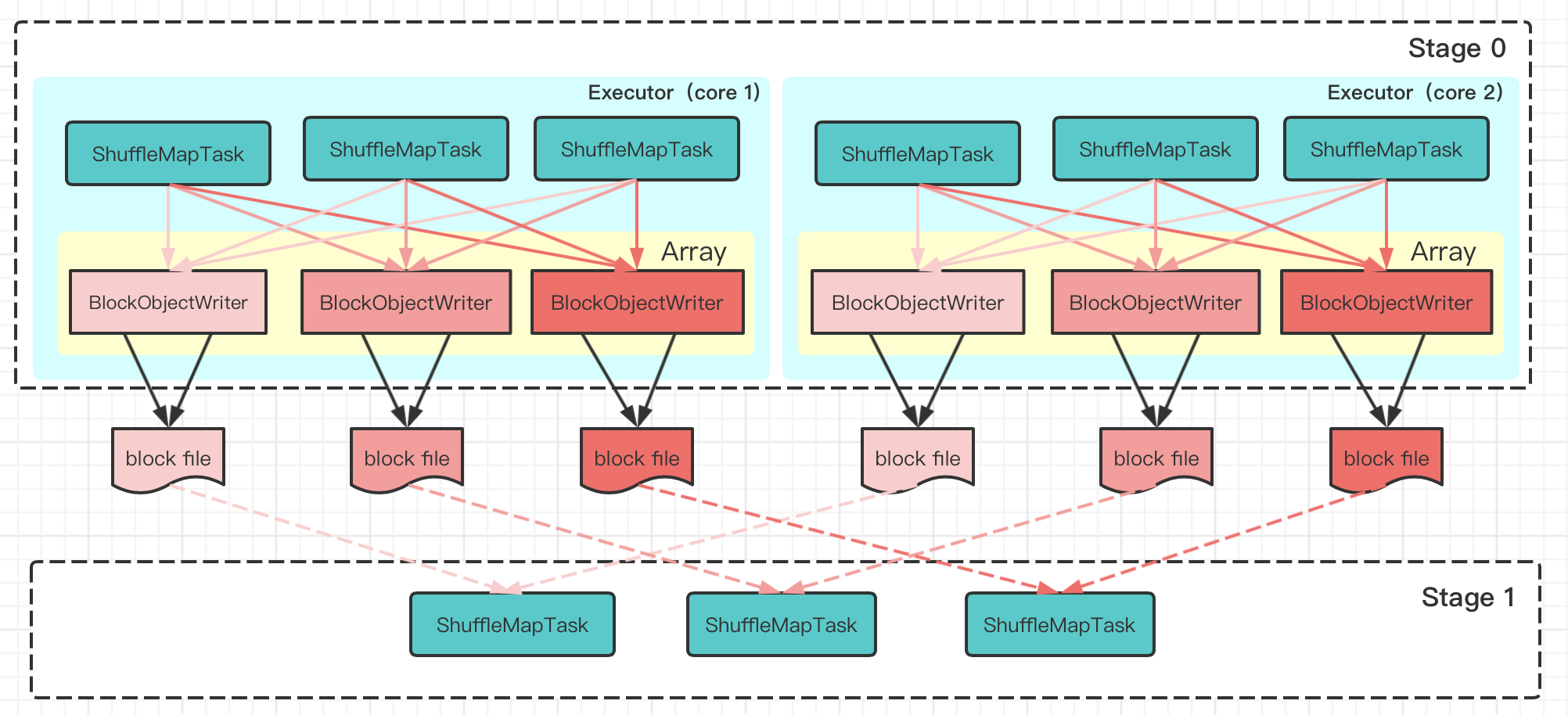
新版HashShuffle的优点:
- 同一个executor里每一个core(也就是同一个线程)会创建R个block file;
- 2个executor,2个core,100个map,3个reduce为例,改进版将会减少文件数100倍:
- 最初版:2 * 2 * 100 * 3 = 1200 个文件
- 改进版:2 * 2 * 3 = 12 个文件
存在的问题:在reduce数量或core数量较大的情况下,依然避免不了大量小文件问题。
4.2、SortShuffleManager
1.1版本引入ShuffleManager之后,除了默认的HashShuffle,还支持了新的SortShuffle。HashShuffle并未解决Shuffle过程中大量小文件的问题,SortShuffle采用了这样的机制:
在满足一定条件时(非bypass场景),map端会对数据进行排序
然后map将数据写入缓存
当缓存装不下时,会溢写入以FileSegment为抽象的磁盘文件
最后将各个segment合并为一个文件,同时将索引写入一个索引文件用于拆分各个segment。
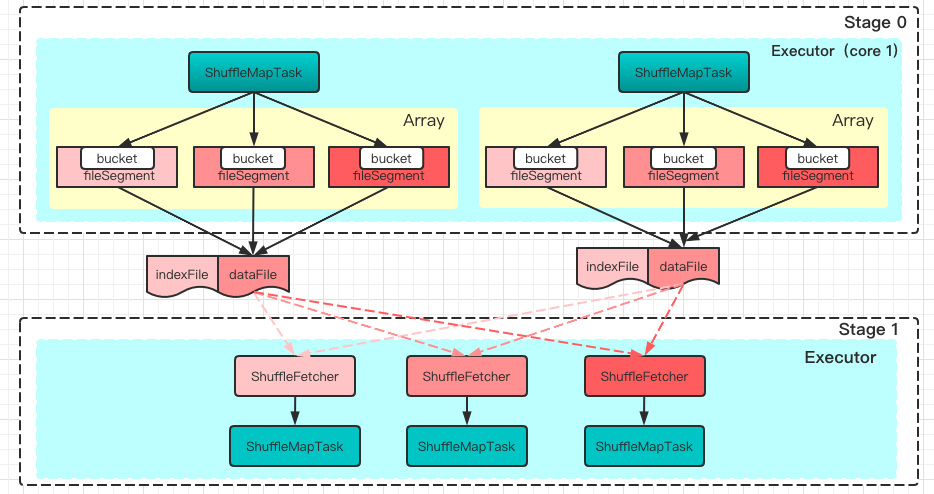
SortShuffleManager的特点:
- 生成的文件数量完全和map数一致,和executor数量,core数量,reduce数量均无关。如100个map生成100个文件。
- 通过spark.shuffle.sort.bypassMergeThreshold开关来决定是否在map端进行排序的优化(毕竟排序是很耗时的)。
- 缓存溢出保护机制。当缓存满了,会自动溢出到文件。
4.3、UnsafeShuffleManager
我们注意到在1.5版本,引入了UnsafeShuffleManager。在小数据量场景下,直接通过unsafe API写数据,这种情况下直接使用对外内存,从而减少JVM的内存使用,避免gc等,unsafe具有很大的优势,效率更高。但同样直接使用对外内存也带来很大的风险,因此,在使用时增加了很多限制:
不依赖任何顺序相关
输出分区数少于 16777216
序列化时,单条记录不大于128MB
虽然增加了诸多限制,但依然存在风险。
从版本迭代演进来看,自1.6版本起,UnsafaShuffleManager不再是ShuffleManager的实现类,同样说明了社区的态度:该方式不是最优的方案。
5、Spark中Shuffle策略的选择
我大约是在16年前后开始接触Spark,经历两个大版本1.6和2.4,先来看看1.6版本中的的shuffle实现。
前面我们说了ShuffleService官方提供有三种:hash,sort,unsafe。我们可以通过指定配置参数spark.shuffle.manager来指定要使用那种shuffle service。
1.6中提供了两种hash和sort。hash存在很多的弊端,2.0+版本不再提供hash shuffle。
在整个shuffle阶段中,shuffle writer尤为重要(这个阶段决定shuffle文件数),以1.6为例,看下Spark是如何为我们选择Shuffle策略的。
整个shuffle的触发是从ShuffleMapTask开始的,它的实现十分短小精悍(核心代码runTask总共27行):
1 | private[spark] class ShuffleMapTask( |
采用何种ShuffleWriter,取决于入参shuffleHandle,而它是由当前rdd的依赖持有的:
1 | writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context) |
通过shuffleHandle获取ShuffleWriter(unsafe,bypass或默认的SortShuffle实现)
1 | override def getWriter[K, V]( |
shuffleHandle是ShuffleManager在注册shuffle时创建的:
1 | val shuffleHandle: ShuffleHandle = _rdd.context.env.shuffleManager.registerShuffle( |
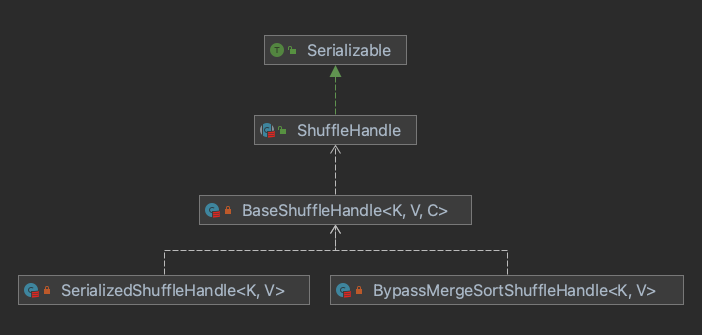
ShuffleHandle的种类由如下三种,其中BaseShuffleHandle 是 SerializedShuffleHandle 和 BypassMergeSortShuffleHandle 的基类:
下面是使用何种ShuffleHandle的源码实现:
1 | override def registerShuffle[K, V, C]( |
6、Spark Shuffle总结
- Shuffle由两个阶段构成 shuffle write 和shuffle read,write被map调用,read被reduce调用。通常write阶段决定了shuffle阶段拉取的文件数,所以整个shuffle的优化历程集中在write上。
- Spark设计之初,并没有抽象出ShuffleManager,一开始采用的hash shuffle方式。
- 自1.1版本开始,抽象出ShuffleManager的shuffle框架,并提供了hash和sort两种实现。
- hash shuffle有两种版本。版本一文件数FN(file number)和map数以及reduce数正相关,即会生成 FN = M * R 个文件,并且bucket缓存使用的map数据结构,极易出现内存溢出问题;版本二进行了优化,和map数没有关系,而是和并发数 C(executor core数量),E(executor数量)以及R(reduce数)正相关,即会生成 FN = C * E * R ;
- sort shuffle有三种实现策略:unsafe,bypass,默认(base)实现。unsafe是使用对外内存,在1.4版本的钨丝计划中引入,适用场景是小数据量。起初允许用户自己指定,由于unsafe需要用户自行对数据量进行预判,往往用户任务的数据量会随着业务的发展而变化,经常会出现任务失败的情况。1.6版本之后,spark在引擎内部做了自动适配。bypass适用于不依赖于map侧的聚合,以及分区数较少的场景(由 spark.shuffle.sort.bypassMergeThreshold(默认值200)控制),由此可见更常用的策略依然还是SortShuffleWriter。
- 在2.0+版本开始,不再提供hash shuffle方式。
附:Spark Shuffle源码解读的心路里程
本来打算最后写一些源码解读的东西,但后来想想势必需要贴大量的源代码(想必也没人爱看),大家更多的难点在于怎么去看源码,没有头绪,没有切入点。所以,最后决定写一下自己Shuffle源码时方法。
- ① 书。其实有太多的pdf,网盘资料等等,码农可能是最推崇白嫖的技能,因人而异,总之在书这件事上不要吝啬自己的钱。
- ② 对比。通过阅读对比大量的大神的帖子,你自然而然地会找到源码的切入点。
- ③ 从最老的版本开始。通常源码的老版本的实现是最初版,比较简单,容易理解。然后慢慢切换高版本,不仅容易上手,而且还能看到整体的迭代脉络。
- ④ 不耻下问。多思考,然后多和身边的大神请教交流。记住要虚心。
最后说下Shuffle这一块我的切入点,我是从ShuffleMapTask这个类切入的,如果你有更好的切入方式,欢迎留言交流。
本文链接: https://stefanxiepj.github.io/archives/2ea6b69f.html
版权声明: 本作品采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 进行许可。转载请注明出处!
